MySQL
MySQL是一个开源、多线程的关系型数据库管理系统(RDBMS)。
1 简介¶
架构¶
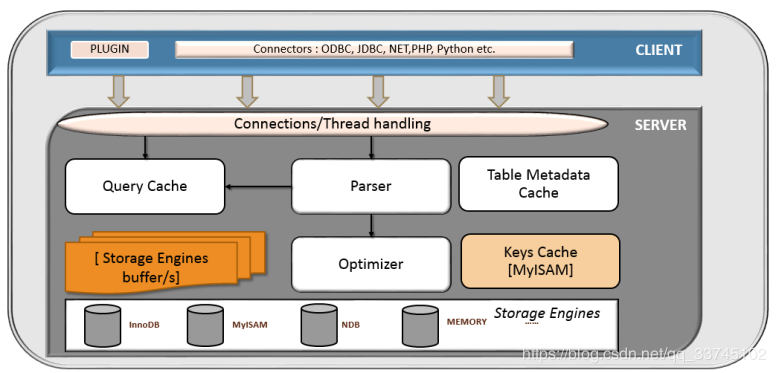
- 连接器(Connector):负责跟客户端建立连接、获取权限、维持和管理连接。
- 查询缓存(Query Cache): 将查询结果按K-V的形式进行缓存,K是查询的语句,V是查询的结果。当一个表发生更新后,该表对应的所有缓存均会失效。
- 分析器(Parser): 分析器有两个功能:^词法分析、语^法分析**。对于一个SQL语句,分析器首先进行词法分析,对SQL语句进行拆分,识别出各个字符串代表的含义。然后就是语法分析,分析器根据定义的语法规则判断SQL是否满足MySQL语法。
- 优化器(Optimizer): 优化器在获取到分析器的结果后,通过表结构和SQL语句选择最佳执行方案,比如:多表关联时,各个表如何进行连接;当表中有索引时,应该怎样选择索引等等。
- key cache: 通常供MyISAM存储引擎缓存索引数据
- 存储引擎: InnoDB, MyISAM, MEMORY, ARCHIVE, CSV.
并发控制¶
在处理并发读或者写时,可以通过由读锁(read lock, 也叫共享锁shared lock)和写锁(write lock, 也叫独占锁exclusive lock)组成的锁系统来解决。读锁是共享的,多个客户在同一时刻可以同时读取同一资源,而互不干扰。写锁是排他的,只有一个用户能执行写入,并防止其他用户读取正在写入的同一资源。
加锁需要消耗资源。锁的各种操作,包括获得锁、检查锁是否已经解除、释放锁等,都会增加系统的开销。锁策略是指在锁的开销和数据的安全性之间寻求平衡。每种MySQL存储引擎都可以实现自己的锁策略和锁粒度。
- 表锁(table lock)会锁定整张表。它是MySQL中最基本的锁策略,并且是开销最小的策略。用户在对表进行写操作(插入、删除、更新等)前,需要先获得锁,然后阻塞其他用户对该表的所有读写操作。
- 行级锁(row lock)可以最大程度地支持并发处理,但也带来了最大的锁开销。MySQL在InnoDB和XtraDB等存储引擎中实现了行级锁。
事务¶
事务(transaction)是数据库应用中完成单一逻辑功能的操作集合。
ACID特性¶
关系型数据库的事务具有ACID特性,即原子性(Atomicity),一致性(Consistency),隔离性(Isolation),持久性(Durability)。
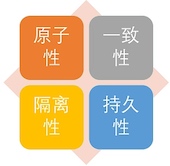
- 事务的原子性是指事务是一个不可再分割的最小工作单元,整个事务中的所有操作要么都执行,要么都不执行,不可能只执行其中的一部分。例如资金从账户A转账到账户B时,需要在账户A中进行取出操作,在账户B中进行存入操作。这两个操作必须保证要么都发生要么都不发生。
- 事务的一致性是指数据库总是从一个一致性的状态转换到另外一个一致性的状态。例如资金转账前后,账户A和B的余额之和应该是保持不变的。
- 事务的隔离性是指一个事务所做的修改在最终提交以前,对其他事务是不可见的。
- 事务的持久性是指事务执行完成后,该事务对数据库的更改就会永久保存到数据库中。例如当资金转账成功后,即使发生系统故障,账户A、B的余额也应该保持转账成功结束后的新值。
隔离级别¶
SQL标准中定义了四种隔离级别,每一种级别都规定了一个事务中所做的修改,哪些在事务内和事务间是可见的,哪些是不可见的。较低级别的隔离通常可以执行更高的并发,系统的开销也更低。
- 未提交读(READ UNCOMMITTED): 事务中的修改,即使没有提交,对其他事务也都是可见的。事务可以读取未提交的数据,这也被称为脏读(dirty read)。在实际应用中一般很少使用。
- 提交读(READ COMMITTED): 一个事务从开始直到提交之前,所做的任何修改对其他事务都是不可见的。也叫做不可重复读(nonrepeatable read),因为执行两次同样查询,可能得到不一样的结果。
- 可重复读(REPEATABLE READ): 在同一个事务中多次读取同样记录的结果是一致的。但无法解决幻读(phantom read)的问题: 当某个事务在读取某个范围内的记录时,另外⼀个事务又在该范围内插⼊了新的记录,当之前的事务再次读取该范围的记录时,会产⽣幻⾏。InnoDB存储引擎通过多版本并发控制(MVCC)解决了幻读的问题。
- 可串行化(SERIAZABLE):所有的事务操作都必须串行操作。这种隔离级别最高,但是牺牲了系统的并发性。简单来说,SERIAZABLE会在读取的每一行数据上都加锁,所以可能导致大量的超时和锁争用的问题。
![]()
死锁¶
MySQL实现了各种死锁检测和死锁超时机制。越复杂的系统,比如InnoDB存储引擎,越能检测到死锁的循环依赖并立即返回一个错误。InnoDB目前处理死锁的方法是,将持有最少行级排他锁的事务进行回滚。
锁的行为和顺序是和存储引擎相关的。死锁的产生有双重原因:有些因为真正的数据冲突,但有些完全是由于存储引擎的实现方式导致的。死锁发生以后,只有部分或者完全回滚其中一个事务,才能打破死锁。
MySQL中的事务¶
MySQL默认采用自动提交(autocommit)模式:如果不是显示地开始一个事务,则每个查询都被当作一个事务执行提交操作。当AUTOCOMMIT=0时,所有的查询都是在一个事务中,直到显式地执行COMMIT提交或者ROLLBACK回滚,这时该事务结束,同时又开始了另外一个事务。
MySQL服务器层不管理事务,事务是由下层的存储引擎实现的。所以在同一个事务中,使用多种存储引擎是不可靠的。如果在事务中混合使用了事务型和非事务型表(例如InnoDB和MyISAM表),该事务需要回滚,那么非事务型的表的变更就无法撤销,这会导致数据库处于不一致的状态,这种情况很难修复。
client and server¶
The server maintains, controls and protects your data, storing it in files on the computer where the server is running in various formats. It listens for requests from client.
For MySQL, mysqld(the d stands for daemon) is the server. mysql is a standard MySQL client. With its text-based interface, a user can log in and execute SQL queries.
MySQL基准测试¶
基准测试是针对系统设计的一种压力测试。通常的目标是为了掌握系统的行为。基准测试不是真实的压力测试,相对来说比较简单。真实压力是不可预期且变化多端的,有时候情况会过于复杂而难以解释。
测试指标
- 吞吐量:单位时间内的事务处理数。这一直是经典的数据库应用测试指标。常用的测试单位是每秒事务数(TPS)。
- 响应时间: 测试任务所需的整体时间。由于测试时间越长,其最大响应时间也可能越大,所以其意义不大。通常可以使用百分比响应时间(percentile response time)来替代最大响应时间。例如,如果95%的响应时间都是5毫秒,则表示任务在95%的时间段内都可以在5毫秒之内完成。
- QPS:每秒查询率(Queries Per Second),是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
2 SQL 语句与管理¶
基本管理命令¶
- The
mysql_safescript is the most common way to startmysqld, because this script can restart the daemon if it crashes. - The
mysqlaccesstool creates user accounts and sets their privileges. - The
mysqladminutility can be used to manage the database server itself from the command-line. - The
mysqlshowtool may be used to examine a server’s status, as well as information about databases and tables. - The
mysqldumputility is the most popular one for exporting data and table structures to a plain-text file, known as adumpfile. - The command
mysql -u root -pis usually used to start the clientmysql, after which the passport should be filled. - The command
mysql -u root -p -e "SELECT User,Host FROM mysql.user;"gives a list of username and host combination on the server.
SQL¶
Glossary of commonly used SQL commands:
ALTER TABLE
ALTER TABLE table_name ADD column datatype;
AND
SELECT column_name(s)
FROM table_name
WHERE column_1 = value_1
AND column_2 = value_2;
AS
SELECT column_name AS 'Alias'
FROM table_name;
AVG
SELECT AVG(column_name)
FROM table_name;
BETWEEN
SELECT column_name(s)
FROM table_name
WHERE column_name BETWEEN value_1 AND value_2;
COUNT
SELECT COUNT(column_name)
FROM table_name;
CREATE TABLE
CREATE TABLE table_name (column1 datatype, column2 datatype, column3 datatype);
DELETE
DELETE FROM table_name WHERE some_column = some_value;
GROUP BY
SELECT COUNT(*)
FROM table_name
GROUP BY column_name;
INNER JOIN
SELECT column_name(s) FROM table_1
JOIN table_2
ON table_1.column_name = table_2.column_name;
INSERT
INSERT INTO table_name (column_1, column_2, column_3) VALUES (value_1, value_2, value_3);
LIKE
SELECT column_name(s)
FROM table_name
WHERE column_name LIKE pattern;
pattern matching enables you to use _ to match any single character and % to match an arbitrary number of characters (including zero characters).
LIMIT
SELECT column_name(s)
FROM table_name
LIMIT number;
MAX
SELECT MAX(column_name)
FROM table_name;
MIN
SELECT MIN(column_name)
FROM table_name;
MIN() is a function that takes the name of a column as an argument and returns the smallest value in that column.
OR
SELECT column_name
FROM table_name
WHERE column_name = value_1
OR column_name = value_2;
ORDER BY
SELECT column_name
FROM table_name
ORDER BY column_name1, column_name2 ASC|DESC;
OUTER JOIN
SELECT column_name(s) FROM table_1
LEFT JOIN table_2
ON table_1.column_name = table_2.column_name;
ROUND
SELECT ROUND(column_name, integer)
FROM table_name;
SELECT
SELECT column_name FROM table_name;
SELECT DISTINCT
SELECT DISTINCT column_name FROM table_name;
SUM
SELECT SUM(column_name)
FROM table_name;
UPDATE
UPDATE table_name
SET some_column = some_value
WHERE some_column = some_value;
WHERE
SELECT column_name(s)
FROM table_name
WHERE column_name operator value;
SELECT * FROM customers WHERE ID=7;
SQL Operators¶
Comparison Operators and Logical Operators are used in the WHERE clause to filter the data to be selected.
Comparison Operators
The following comparison operators can be used in the WHERE clause:
| Operator | Description |
|---|---|
| = | Equal |
| != | Not equal |
| > | Greater than |
| < | Less than |
| >= | Greater than or equal |
| <= | Less than or equal |
| BETWEEN | Between an inclusive range |
BETWEEN Operator:
SELECT * FROM customers
WHERE ID BETWEEN 3 AND 7;
Logical Operators
Logical operators can be used to combine two Boolean values and return a result of true, false, or null.
The following operators exists in SQL:
| Operator | Description |
|---|---|
| AND | TRUE if both expressions are TRUE |
| OR | TRUE if either expression is TRUE |
| IN | TRUE if the operand is equal to one of a list of expressions |
| NOT | Returns TRUE if expression is not TRUE |
The IN Operator:
SELECT * FROM customers
WHERE City IN ('New York', 'Los Angeles', 'Chicago');
The NOT IN Operator:
SELECT * FROM customers
WHERE City NOT IN ('New York', 'Los Angeles', 'Chicago');
Functions¶
The UPPER function converts all letters in the specified string to uppercase.
The LOWER function converts the string to lowercase.
The following SQL query selects all Lastnames as uppercase:
SELECT FirstName, UPPER(LastName) AS LastName
FROM employees;
The SQRT function returns the square root of given value in the argument.
Similarly, the AVG function returns the average value of a numeric column.
The SUM function is used to calculate the sum for a column's values.
The MIN function is used to return the minimum value of an expression in a SELECT statement.
E.g. you might wish to know the minimum salary among the employees:
SELECT MIN(salary) AS Salary FROM employees;
Subqueries¶
A subquery is a query within another query. Enclose the subquery in parentheses.
E.g.
SELECT FirstName, Salary FROM employees
WHERE Salary > (SELECT AVG(Salary) FROM employees)
ORDER BY Salary DESC;
Joining Tables¶
SQL can combine data from multiple tables. In SQL, 'joining tables' means combining data from two or more tables. A table join creates a temporary table showing the data from the joined tables.
To join tables, specify them as a comma-separated list in the FROM clause:
SELECT customers.ID, customers.Name, orders.Name, orders.Amount
FROM customers, orders
WHERE customers.ID = orders.Customer_ID
ORDER BY customers.ID
Types of Join
SELECT table1.column1, table2.column2...
FROM table1 [INNER | LEFT | RIGHT | FULL OUTER] JOIN table2
ON table1.column_name = table2.column_name;
The following are types of JOIN that can be used in SQL:
INNER JOIN: returns rows when there is a match between the tables.LEFT JOIN: returns rows from the left table, even if there are no matches in the right table.RIGHT JOIN: returns rows from the right table, even if there are no matches in the left table.FULL OUTER JOIN: return rows from the both left and right tables even if there’s no match
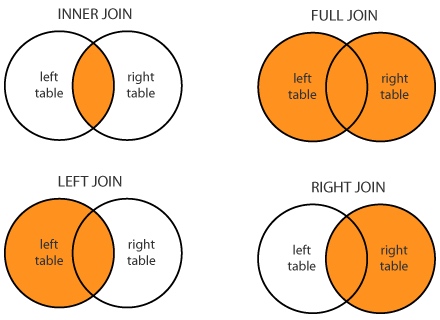
Example: Left, Right, Outer, Inner, Cross Joins
Simple Example: Let's say you have a Students table, and a Lockers table. In SQL, the first table you specify in a join, Students, is the LEFT table, and the second one, Lockers, is the RIGHT table.
Each student can be assigned to a locker, so there is a LockerNumber column in the Student table. More than one student could potentially be in a single locker, but especially at the beginning of the school year, you may have some incoming students without lockers and some lockers that have no students assigned.
For the sake of this example, let's say you have 100 students, 70 of which have lockers. You have a total of 50 lockers, 40 of which have at least 1 student and 10 lockers have no student.
INNER JOIN(内连接) is equivalent to "show me all students with lockers". Any students without lockers, or any lockers without students are missing. Returns 70 rows.
LEFT OUTER JOIN(左连接) would be "show me all students, with their corresponding locker if they have one". This might be a general student list, or could be used to identify students with no locker. Returns 100 rows.
RIGHT OUTER JOIN(右连接) would be "show me all lockers, and the students assigned to them if there are any". This could be used to identify lockers that have no students assigned, or lockers that have too many students. Returns 80 rows (list of 70 students in the 40 lockers, plus the 10 lockers with no student).
FULL OUTER JOIN(全连接) would be silly and probably not much use. Something like "show me all students and all lockers, and match them up where you can" . Returns 110 rows (all 100 students, including those without lockers. Plus the 10 lockers with no student).
CROSS JOIN is also fairly silly in this scenario.
It doesn't use the linked lockernumber field in the students table, so you basically end up with a big giant list of every possible student-to-locker pairing, whether or not it actually exists.
Returns 5000 rows (100 students x 50 lockers). Could be useful (with filtering) as a starting point to match up the new students with the empty lockers.
cartesian product
When you do cross join you will get cartesian product(笛卡尔积) of rows from tables in the join. In other words, it will produce rows which combine each row from the first table with each row from the second table.
Backing up and Restoring¶
Backing up
mysqldump -u user -p database_name > /data/backups/all-dbs.sql
mysql -u user -p < all-dbs.sql
创建数据库¶
创建数据库时设置字符集,可以避免出现中文乱码:
CREATE DATABASE database_name DEFAULT CHARACTER SET utf8;
类似的,创建表时,使用DEFULAT CHARSET=utf8:
CREATE TABLE table_name () DEFAULT CHARSET=utf-8;
远程登录¶
MySQL默认情况下只允许本地连接。想要远程连接MySQL数据库,需要授权。
grant all privileges on 库名.表名 to '用户名'@'IP地址' identified by '密码' with grant option;
flush privileges; //刷新MySQL的系统权限相关表
例如给在远程登录的root用户授予所有权限:
mysql> use mysql;
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
mysql> flush privileges;
3 Schema与数据库类型优化¶
选择优化的数据类型¶
不管存储哪种类型的数据,下面的几个简单的原则都有助于做出更好的选择:
- 更小的通常更好:一般情况下,应该尽量使用可以正确存储数据的最小数据类型。更小的数据类型通常更快,因为它们占用更少的磁盘、内存和CPU缓存,并且处理时需要的CPU周期也更少。
- 简单就好:简单数据类型的操作通常耗费更少的CPU周期。例如整型比字符操作代价更低,因为字符集和校对规则使字符比整型比较更复杂。
- 连量避免NULL:通常情况下最好指定列为NOT NULL,除非真的需要存储NULL值。因为如果查询中包含NULL的列,对MySQL来说更难优化,NULL的列使得索引、索引统计和值比较都更复杂。
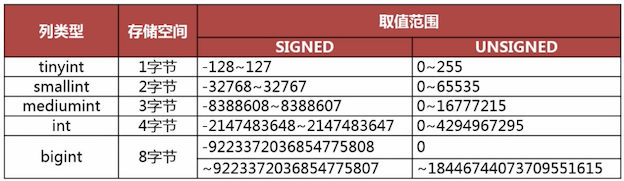
整数类型¶
不同的整数类型使用不同的存储空间。整数类型有可选的UNSIGNED属性,表示不允许负值。MySQL可以为整数类型指定宽度,例如INT(11),但是它并不会限制值的合法范围,只是规定了显示字符的个数而已。
实数类型¶
FLOAT和DOUBLE类型支持使用标准的浮点运算进行近似计算。DECIMAL类型支持精确计算,由MySQL自身实现。

字符串类型¶
VARCHAR和CHAR是两种最重要的字符串类型。它们的具体存储方式和存储引擎相关。
VARCHAR类型的存储特点
- VARCHAR用于存储变长字符串,只占用必要的存储空间。VARCHAR和CHAR定义的是字符的长度,不是字节的长度。
- varchar(5)和varchar(200)存储“MYSQL”字符串的性能不同
- VARCHAR需要额外1或2个字节记录字符串的长度
- 列的最大长度小于255则只占用1个额外字节用于记录字符串长度
- 列的最大长度大于255则要占用2个额外字节用于记录字符串长度
使用场景
- 字符串列的最大长度比平均长度大很多
- 字符串列很少被更新,所以碎片不是问题
- 使用了UTF-8这样复杂的字符集存储字符串,每个字符都适用不同的字节数进行存储
CHAR类型的存储特点
- Char类型是定长的,根据定义的字符串长度分配足够的空间
- 字符串存储在CHAR类型的列中会删除末尾的空格
- 最大宽度为255
使用场景
- 适合存储长度相近的值,例如MD5值
- 适合存储短字符串
- 适合存储经常更新的字符串列
时间和日期类型¶
MySQL提供两种相似的日期类型:DATETIME和TIMESTAMP。
- DATETIME类型
- 以YYYY-MM-DD HH:MM:SS 格式存储日期时间
- datetime类型与时区无关,占用8个字节的存储空间
- TIMESTEP类型
- 存储了由格林尼治时间1970年1月1日到当前时间的秒数
- 以YYYY-MM-DD HH:MM:SS的格式显示,占用4个字节
- 显示依赖于所指定的时区,在行的数据修改时可以自动修改timestamp列的值
自动更新
在设计表候,有时候需要将记录的创建时间和最后更新时间记录下来。尤其是可能需要做数据同步或者对数据新鲜度有要求的表,例如将一个月前的订单数据归档等等。最好把这个需求丢给数据库服务器管理,而不是在应用程序中对每一条插入或更新语句设置创建时间和最后更新时间字段。在mysql中,这实现起来很容易。只需要借助于DEFAULT CURRENT_TIMESTAMP 和 ON UPDATE CURRENT_TIMESTAMP。
--创建测试表
CREATE TABLE `timestampTest` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`last_modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
--检测默认值,插入测试数据
INSERT INTO timestampTest (name) VALUES ('aa'),('bb'),('cc');
--检测自动更新,更新某条数据
UPDATE timestampTest SET name = 'ab' WHERE id = 1;
有时候可能只需要存储日期和时间,这适合DATE类型和TIME类型:
- DATE类型用于保存1000-01-01到9999-12-31之间的日期
- TIME类型用于存储时间数据,格式为HH:MM:SS
存储日期时间数据的注意事项
不要使用字符串类型来存储日期时间数据,原因是日期时间类型通常比字符串占用的存储时间小,而且在进行查找过滤时可以利用日期来进行对比,除此之外还有丰富的日期处理函数。
表设计中的陷阱¶
请避免一下创建MySQL表时的错误:
- 太多的列
- 太多的关联:如果希望查询执行得快且并发行好,单个查询最好在12个表内做关联。
- 不合适的NULL:虽然尽量不要使用NULL,但是在某些场景中使用NULL可能比某个神奇常数更好。例如使用-1代表一个未知的整数可能导致代码复杂很多,并且容易引入bug。再例如使用'0000-00-00'代替未知的日期。
范式和反范式¶
数据库设计范式
为了设计出没有数据冗余和数据维护异常的数据库结构
数据库三范式
数据库设计的第一范式
- 数据库表中的所有字段都只具有单一属性
- 单一属性的列由基本的数据类型所构成的
- 设计出来的表都是简单的二维表
数据库设计的第二范式
- 要求一个表中具有一个业务主键,也就是说符合第二范式的表中不能存在非主键列对部分主键的依赖关系
数据库设计的第三范式
- 指每一个非主属性既不部分依赖于也不传递依赖于业务主键,也就是在第二范式的基础上消除了非主属性对主键的传递依赖。
需求分析及逻辑注册
用户登陆及用户管理功能
- 用户必须注册并登陆系统才能进行网上交易
- 同一时间一个用户只能在一个地方登陆
- 用户信息: 用户名,密码,手机号,姓名,注册日期,在线状态,出生日期
商品展示及商品管理功能
- 商品信息: 商品名称,分类名称,出版社名称,图书价格,图书描述,作者
- 分类信息:分类名称,分类描述
- 商品分类:商品名称,分类名称
供应商管理功能
- 供应商信息:出版社名称,地址,电话,联系人,银行账号
在线销售功能
- 订单表:订单编号,下单用户名,下单日期,支付金额,物流单号
- 订单商品关联表:订单编号,订单商品分类,订单商品名,商品数量
范式化设计的优缺点
优点:
- 可以尽量的减少数据冗余,数据表更新快体积小,
- 范式化的更新操作比反范式化更快
- 范式化的表通常比反范式化更小
缺点:
- 对于查询需要对多个表进行关联
- 更难进行索引优化
反范式化优缺点:
优点:
- 可以减少表的关联
- 可以更好的进行索引优化
缺点:
- 存在数据冗余及数据维护异常
- 对数据的修改需要更多的成本
缓存表和汇总表¶
加快ALTER TABLE操作的操作¶
4 InnoDB存储引擎¶
InnoDB是MySQL默认事务型存储引擎,拥有良好的性能和自动崩溃恢复特性。
- 设计目的:处理大量的短期(short-lived)事务(短期事务大部分情况是正常提交的,很少被回滚)
- 特点:
- 数据存储在表空间(tablespace)中,由InnoDB管理的黑盒子,由一系列的数据文件组成。
- 采用MVVC支持高并发,实现四个标准的隔离级别,默认为REPEATABLE READ,并且通过间隙锁(next-key locking)策略使得InnoDB锁定查询涉及的行,还会对索引中的间隙进行锁定,防止幻读出现。
- 基于聚簇索引(clustered index)建立,对主键查询有很高的性能。但是二级索引(secondary index,非主键索引)必须包含主键列,如主键索引过大,其它的所有索引都会很大。
- 从磁盘读取数据采用可预测性预读、自动在内存中创建hash索引以加速读操作的自适应索引(adaptive hash index)、加速插入操作的插入缓冲区(insert buffer)
- 通过一些机制和工具支持真正的热备份
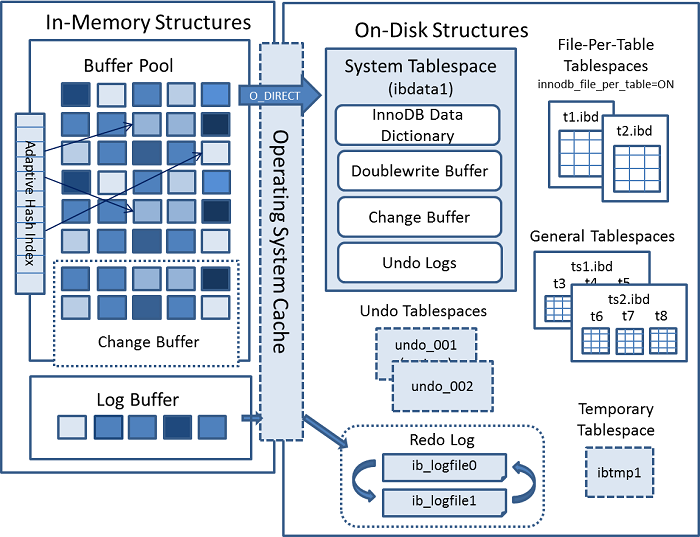
从InnoDB存储引擎的逻辑结构看,所有数据都被逻辑地存放在一个空间内,称为表空间(tablespace),而表空间由段(sengment)、区(extent)、页(page)组成:
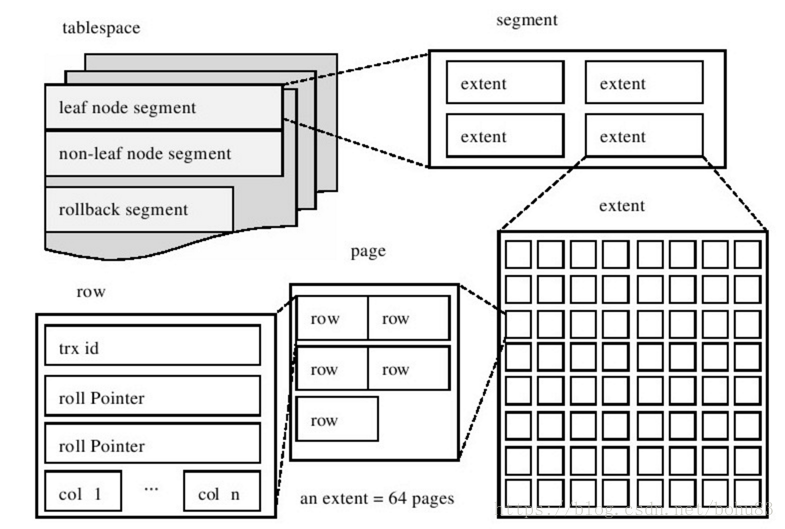
- 表空间(Tablespace):一个逻辑容器,表空间存储的对象是段,在一个表空间中可以有一个或多个段,但是一个段只能属于一个表空间。数据库由一个或多个表空间组成,表空间从管理上可以划分为系统表空间(system tablespace)、用户表空间、撤销表空间(undo tablespace)、临时表空间(temporary tablespace)等。
- 段(Segment):数据库中的分配单位,不同类型的数据库对象以不同的段形式存在。当我们创建数据表、索引的时候,就会相应创建对应的段,比如创建一张表时会创建一个表段,创建一个索引时会创建一个索引段。段由一个或多个区组成。
- 区(extent): 在文件系统是一个连续分配的空间(连续的64个页)。为了保证页的连续性,InnoDB存储引擎每次从磁盘一次申请多个区。
- 页(Page):InnoDB存储引擎磁盘管理的最小单位,每个页默认16KB,可以通过参数
innodb_page_size设置页的大小。
文件格式¶
MySQL使用InnoDB存储表时,会将表的定义(.frm)和数据索引(.ibd)分开存储。MySQL的目录结构为:
|--- mysql
|--- data
|--- ib_logfile0
|--- ib_logfile1
|--- ibdata1
|--- 数据库
|--- 表名.frm
|--- 表名.ibd
|--- mysql
|--- data
|--- 数据库
|--- 表名.frm
|--- 表名.myd
|--- 表名.myi
|--- 表名.log
.frm文件:保存了每个表的元数据,包括表结构的定义等,该文件与数据库引擎无关。.ibd文件:InnoDB引擎开启了独立表空间(my.ini中配置innodb_file_per_table = 1)产生的存放该表的数据和索引的文件。ibdata文件:系统表空间文件,存储InnoDB系统信息、用户数据库表数据、索引ib_logfile文件:日志文件
锁¶
InnoDB支持多粒度锁(multiple granularity locking),允许行级锁和表级锁共存。意向锁(Intention Locks)是一种不与行级锁冲突的表级锁,分为
- 意向共享锁(intention shared lock, IS): 事务有意向对表中的某些行加共享锁(S锁)
- 事务要获取某些行的S锁,必须先获得表的IS锁
SELECT column FROM table ... LOCK IN SHARE MODE;
- 意向排他锁(intention exclusive lock, IX): 事务有意向表中的某些行加排他锁(X锁)
- 事务要获取某些行的X锁,必须先获得表的IX锁
SELECT column FROM table ... FOR UPDATE;
意向锁是由数据引擎自己维护的,用户无法手动操作意向锁,在为数据行加共享/排他锁之前,InnoDB会先获取该数据行所在表格的意向锁。
多版本并发控制¶
https://dev.mysql.com/doc/refman/8.0/en/innodb-multi-versioning.html
MySQL的大多数事务型存储引擎实现的都不是简单的行级锁。基于并发性能的考虑,它们一般都同时实现了多版本并发控制(MVCC)。可以认为MVCC是行级锁的一个变种,但是它在很多情况下避免了加锁操作,因此开销更低。
InnoDB的内部实现中为每一行数据增加了三个隐藏列用于实现MVCC。
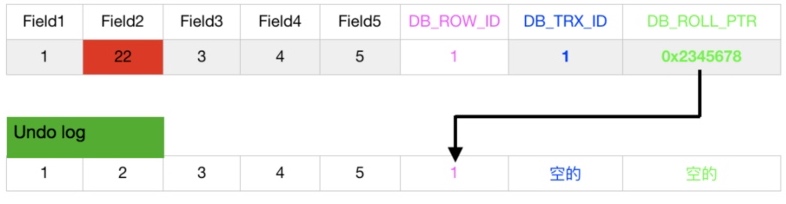
- DB_ROW_ID :6字节,包含一个随着新行插入而单调递增的行ID, 当由innodb自动产生聚集索引时,聚集索引会包括这个行ID的值,否则这个行ID不会出现在任何索引中。
- DB_TRX_ID: 6字节, 用来标识最近一次对本行记录做修改(insert|update)的事务的标识符, 即最后一次修改(insert|update)本行记录的事务id。delete操作在内部来看是一次update操作,更新行中的删除标识位DELELE_BIT。
- DB_ROLL_PTR: 7字节, 指向当前数据的undo log记录,回滚数据通过这个指针来寻找记录被更新之前的内容信息。
- DELELE_BIT:用于标识该记录是否被删除
UndoLog
- Undo log保存在Undo tablespace,
- 在回滚段中的undo logs分为: insert undo log 和 update undo log
- insert undo log : 事务对insert新记录时产生的undolog, 只在事务回滚时需要, 并且在事务提交后就可以立即丢弃。
- update undo log : 事务对记录进行delete和update操作时产生的undo log, 不仅在事务回滚时需要, 一致性读也需要,所以不能随便删除,只有当数据库所使用的快照中不涉及该日志记录,对应的回滚日志才会被purge线程删除。
数据操作
- insert:创建一条记录,DB_TRX_ID为当前事务ID,DB_ROLL_PTR为NULL。
- delete:将当前行的DB_TRX_ID设置为当前事务ID,DELELE_BIT设置为1。
- update:复制一行,新行的DB_TRX_ID为当前事务ID,DB_ROLL_PTR指向上个版本的记录,事务提交后DB_ROLL_PTR设置为NULL。
- select
- 只查找创建早于当前事务ID的记录,确保当前事务读取到的行都是事务之前就已经存在的,或者是由当前事务创建或修改的;
- 行的DELETE BIT为1时,查找删除晚于当前事务ID的记录,确保当前事务开始之前,行没有被删除。
MySQL的一致性读,是通过一个叫做read view的结构来实现的
设要读取的行的最后提交事务id(即当前数据行的稳定事务id)为 trx_id_current, 当前新开事务id为 new_id, 当前新开事务创建的快照read view 中最早的事务id为up_limit_id, 最迟的事务id为low_limit_id(注意这个low_limit_id=未开启的事务id=当前最大事务id+1)
比较:
- trx_id_current < up_limit_id, 这种情况比较好理解, 表示, 新事务在读取该行记录时, 该行记录的稳定事务ID是小于, 系统当前所有活跃的事务, 所以当前行稳定数据对新事务可见, 跳到步骤5.
- trx_id_current >= trx_id_last, 这种情况也比较好理解, 表示, 该行记录的稳定事务id是在本次新事务创建之后才开启的, 但是却在本次新事务执行第二个select前就commit了,所以该行记录的当前值不可见, 跳到步骤4。
- trx_id_current <= trx_id_current <= trx_id_last, 表示: 该行记录所在事务在本次新事务创建的时候处于活动状态,从up_limit_id到low_limit_id进行遍历,如果trx_id_current等于他们之中的某个事务id的话,那么不可见, 调到步骤4,否则表示可见。
- 从该行记录的 DB_ROLL_PTR 指针所指向的回滚段中取出最新的undo-log的版本号, 将它赋值该 trx_id_current,然后跳到步骤1重新开始判断。
- 将该可见行的值返回。
MySQL的InnoDB存储引擎默认事务隔离级别是RR(可重复读), 是通过 "行排他锁+MVCC" 一起实现的, 不仅可以保证可重复读, 还可以部分防止幻读, 而非完全防止。
5 其他存储引擎¶
MyISAM 存储引擎¶
支持全文索引、压缩、空间函数(GIS),不支持事务和行级锁,并且崩溃后无法安全恢复。对于只读数据,或者表比较小,可以忍受修复(repair)操作,可以考虑MyISAM。
- 存储:表以.MYD和.MYI的数据文件和索引文件存储在文件系统。
- 特性:
- 加锁与并发:对整张表而不是特定行加锁。读取时对读到的表加共享锁,写入时则加排它锁。支持并发插入(CONCURRENT INSERT),在读取查询的同时,也可以插入新的数据。
- 修复:与事务恢复以及崩溃恢复是不同的概念。速度慢,可能会导致数据丢失。通过CHECK TABLE mytable 检查表的错误,REPAIR TABLE mytable 进行修复。
- 索引特性:支持全文索引,这是基于分词创建的索引。即使是BOLB和TEXT等长字段,也可以基于前500个字符创建索引。
- 延迟更新索引键(Delayed Key Write):如指定了DELAY_KEY_WRITE,每次修改执行完成时,不会将修改的索引数据写入磁盘而是写到内存中的键缓存区(in-memory key buffer),只有在清理键缓存区或关闭表的时候才会写入磁盘。可极大提升写入性能,但可能在数据库或主机崩溃时造成索引损坏而执行修复操作。
- 压缩表:只进行读操作可采用压缩表,极大减少磁盘占用空间以及IO,从而提升查询性能。
- 性能:设计简单,数据以紧密格式存储,在某些场景下的性能很好。最典型的性能问题为表锁。
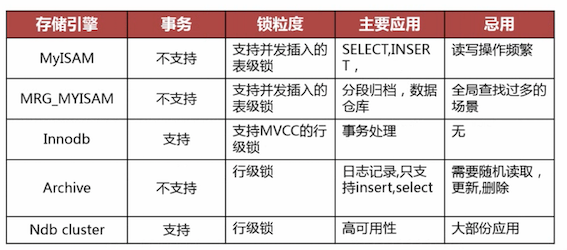
选择合适的存储引擎¶
除非需要用到某些InnoDB不具备的特性,并且没有其它办法可以代替,否则都应该优先选择InnoDB引擎。
6 查询性能优化¶
MySQL数据库结构优化¶
数据库结构优化的目的
减少数据冗余 尽量避免数据维护中出现更新,插入和删除异常 节约数据存储空间 提高查询效率
数据库结构设计的步骤
需求分析:全面了解产品设计的存储需求 逻辑设计:设计数据的逻辑存储结构 物理设计:根据所使用的数据库特点进行表结构设计 维护优化:根据实际情况对索引、存储结构进行优化
物理设计:根据所选择的关系型数据库的特点对逻辑模型进行存储结构设计
- 定义数据库、表及字段的命名规范
- 选择合适的存储引擎
- 为表中的字段选择合适的数据类型
- 建立数据库结构
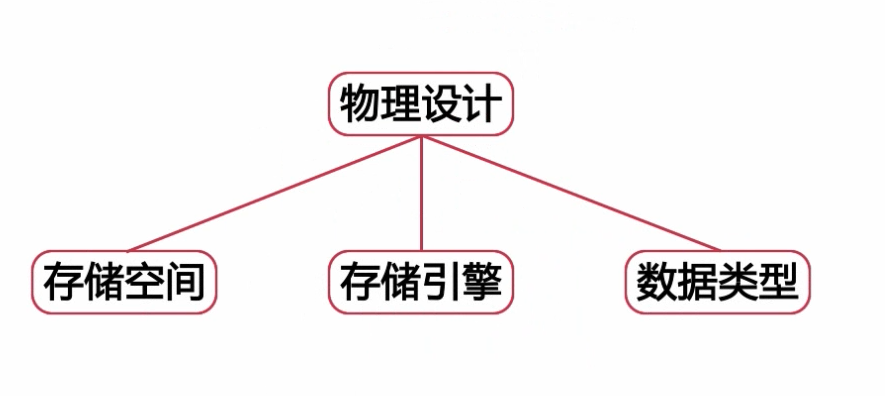
定义数据库、表及字段的命名规范
- 数据库、表及字段的命名要遵循可读性原则 MySQL对大小写敏感
- 数据库、表及字段的命名要遵循表意性原则
- 数据库、表及字段的命名要遵循长名原则
为表中的字段选择合适的数据类型:当一个列可以选择多种数据类型时,应该优先考虑数字类型,其次是日期或二进制类型,最后是字符类型。对于相同级别的数据类型,应该优先选择占用空间小的数据类型。
如何为Innodb选择主键
- 主键应该尽可能小
- 主键应该是顺序增常的,增加数据的插入效率
- Innodb的主键和业务主键可以不同的
数据库索引优化¶
B树和哈希索引¶
B树索引的特点
- 以B+树的结构存储数据
- 能够加快数据的查询速度
- 更适合进行范围查找
在什么情况下可以用到B树索引
- 全值匹配的查询 order_sn="98349"
- 匹配最左前缀的查询
- 匹配列前缀的查询 order_sn like "98843%'
- 匹配范围值的查询 order_sn > '235343' and order_sn < '236556'
- 精确匹配左前列并范围匹配另外一列
- 只访问索引的查询
B树索引的使用限制
- 不是按照索引最左列开始查找
- 使用索引时不能跳过索引中的列
- NOT in 和<> 操作无法使用索引
- 如果查询中有某个列的范围查询,则其右边所有列都无法使用索引
Hash索引的特点
- 基于哈希表实现的,只有查询条件精确匹配哈希索引中的所有列时,才能够使用到哈希索引
- 对于哈希索引中的所有列,存储引擎都会为每一行计算一个哈希码,哈希索引中存储的就是哈希码。
哈希索引的限制
- 哈希索引必须进行二次查找
- 无法用于排序
- 无法进行范围查找
- 哈希码的计算可能存在哈希冲突
MySQL常见索引和各种索引区别
PRIMARY KEY(主键索引) ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
UNIQUE(唯一索引) ALTER TABLE `table_name` ADD UNIQUE (`column`)
INDEX(普通索引) ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
FULLTEXT(全文索引) ALTER TABLE `table_name` ADD FULLTEXT ( `column` )
组合索引 ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
** 普通索引:最基本的索引,没有任何限制 * 唯一索引:与"普通索引"类似,不同的就是:索引列的值必须唯一,但允许有空值。 * 主键索引:它 是一种特殊的唯一索引,不允许有空值。 * 全文索引:仅可用于 MyISAM 表,针对较大的数据,生成全文索引很耗时好空间。 * 组合索引:为了更多的提高mysql效率可建立组合索引,遵循”最左前缀“原则。
使用索引好处和缺陷¶
为什么要使用索引
- 索引大大减少了存储引擎需要扫描的数据量;
- 索引可以帮助我们进行排序以避免使用临时表;
- 索引可以把随机I/O变为顺序I/O。
索引不是越多越好
- 索引会增加写操作的成本;
- 太多的索引会增加查询优化器的选择时间。
索引就好比一本书的目录,它会让你更快的找到内容,显然目录(索引)并不是越多越好,假如这本书1000页,而有500页是目录,它当然效率低,目录是要占纸张的,而索引是要占磁盘空间的。
索引优化策略¶
索引列上不能使用表达式和函数
select * from product
where to_days(out_date) - to_days(current_date) <= 30
select * from product
where out_date <= date_add(current_time, interval 30 day)
前缀索引和索引列的选择性
create index index_name ON table(col_name(n));
索引的选择性是不重复的索引值和表的记录数的比值。
联合索引:如何选择索引列的顺序
- 经常会被使用到的列优先
- 选择性高的列优先
- 宽度小的列优先
如果⼀个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称 之为“覆盖索引”
SQL查询优化¶
获取有性能问题SQL的三种方式
- 通过用户反馈获取存在性能问题的SQL;
- 通过慢查日志获取存在性能问题的SQL;
- 实时获取存在性能问题的SQL;
MySQL提供了慢查日志分析的相关配置参数:
slow_query_log # 启动停止记录慢查日志,慢查询日志默认是没有开启的可以在配置文件中开启(on)
slow_query_log_file # 指定慢查日志的存储路径及文件,日志存储和数据从存储应该分开存储
long_query_time # 指定记录慢查询日志SQL执行时间的阀值默认值为10秒通常,对于一个繁忙的系统来说,改为0.001秒(1毫秒)比较合适
log_queries_not_using_indexes #是否记录未使用索引的SQL
可以用mysqldumpslow和pt-query-digest分析慢查询:
pt-query-digest --explain h=127.0.0.1,u=root,p=p@ssWord slow-mysql.log
也可以实时获取有性能问题的SQL(推荐)
# 查询当前服务器执行超过60s的SQL,可以通过脚本周期性的来执行这条SQL,就能查出有问题的SQL。
SELECT id,user,host,DB,command,time,state,info
FROM information_schema.processlist
WHERE TIME>=60
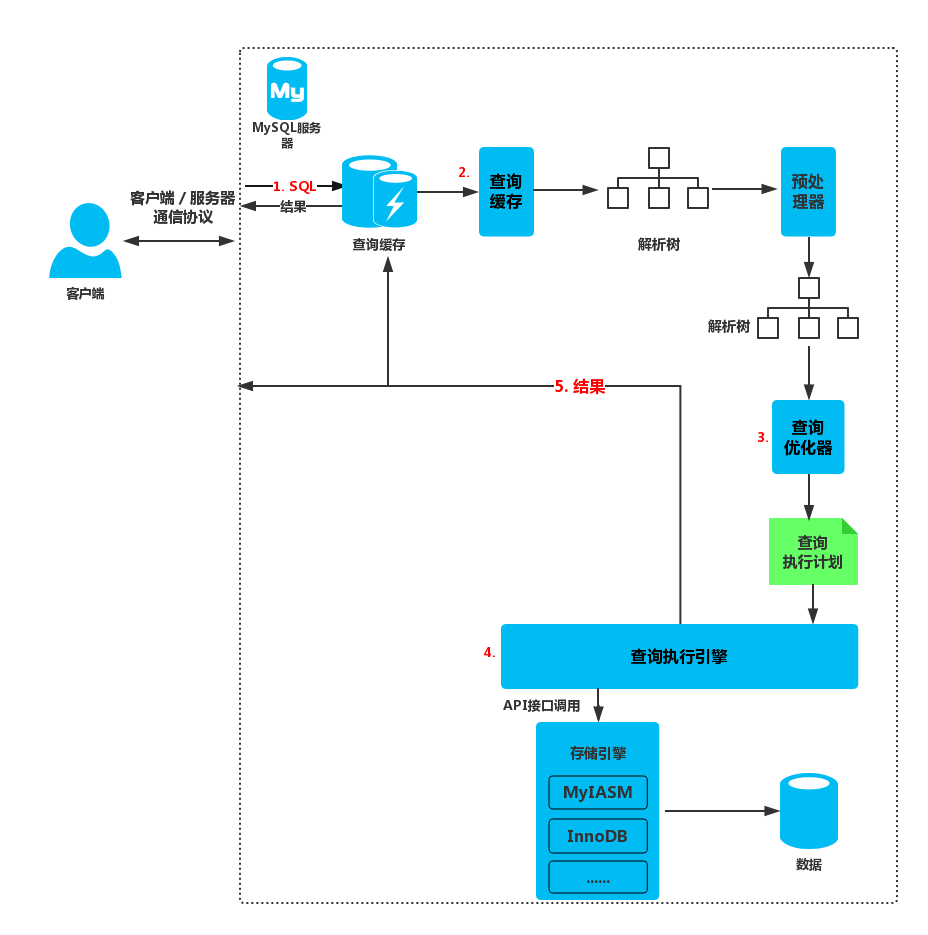 过上图可以清晰的了解到MySql查询执行的大致过程:
过上图可以清晰的了解到MySql查询执行的大致过程:
- 发送SQL语句。
- 查询缓存,如果命中缓存直接返回结果。
- SQL解析,预处理,再由优化器生成对应的查询执行计划。
- 执行查询,调用存储引擎API获取数据。
- 返回结果。
缓存查找是利用对大小写敏感的哈希查找来实现的,Hash查找只能进行全值查找(sql完全一致),如果缓存命中,检查用户权限,如果权限允许,直接返回,查询不被解析,也不会生成查询计划。 在一个读写比较频繁的系统中,建议关闭缓存,因为缓存更新会加锁。将query_cache_type设置为off,query_cache_size设置为0。
7 MySQL 高可用架构设计¶
mysql复制功能提供分担读负载。
- 实现在不同服务器上的数据分布,利用二进制日志增量进行,不需要太多的带宽,但是使用基于行的复制在进行大批量的更改时,会对带宽带来一定的压力,特别是跨IDC环境下进行复制
- 实现数据读取的负载均衡
- 增强了数据的安全性,
二进制日志¶
二进制日志记录了所有对Mysql数据库的修改事件,包括增删改查事件和对表结构的修改事件。二进制日志文件记录的是成功执行了的操作,对于失败的操作不会记录。我们可以通过mysql提供的binlog工具来查看二进制日志。
在记录二进制日志时,mysql提供了3种格式进行存储,可以通过binlog_format来控制使用哪种格式进行记录。
- binlog_format=STATEMENT
- 日志记录量相对较小,节约复制时的磁盘及网络
- 缺点:1.必须要记录上下文信息,保证语句从服务器上执行结果和在主服务器上相同。2.对于特定函数如UUID(),user()这样非确定性函数还是无法复制,所以可能造成Mysql复制的主备服务器数据不一致。
- binlog_format=ROW
- 相比于段格式,如果同一SQL语句修改了10000条数据的情况下,基于段的日志格式只会记录这个SQL语句,基于行的日志会有10000条记录分别记录每一行的数据修改。
- 记录日志量较大。
- 使Mysql主从复制更加安全;对每一行数据的修改比基于段的复制高效;另外对于误操作而修改了数据库中的数据,同时又没有备份可以恢复时,我们就可以通过分析二进制日志,对日志中记录的数据修改操作做反向处理的方式来达到恢复数据的目的。
主从复制流程¶
https://devopscube.com/setup-mysql-master-slave-replication/ https://www.cnblogs.com/clsn/p/8150036.html
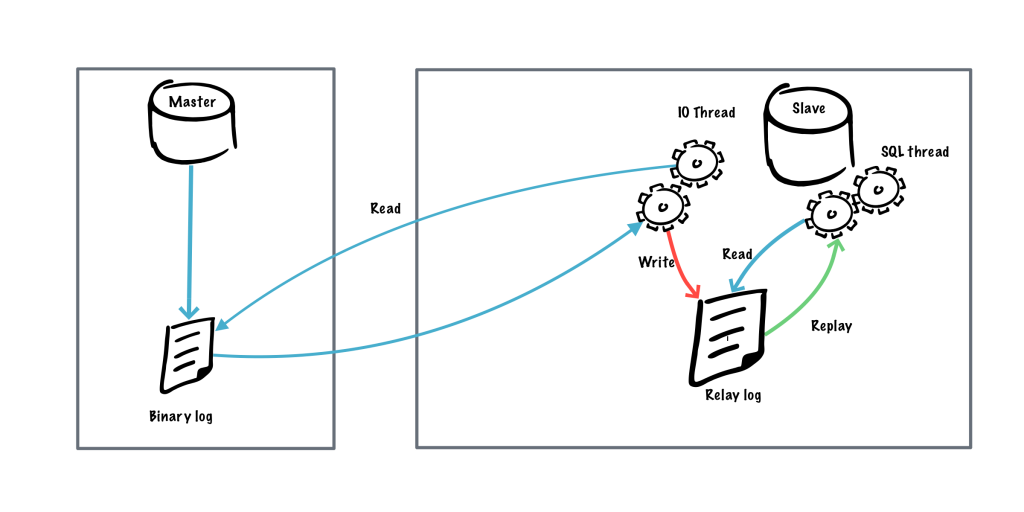
- All database operations are copied to the master’s binary log.
- Salves connect to the master and asks for the data.
- The slave servers get the masters binary log.
- Slaves then apply the binary log to its relay log.
- The relay log is read by the SQL thread process and it applies all the operations/data to the slave’s database and its binary log.
-
https://dev.mysql.com/doc/refman/5.7/en/innodb-architecture.html ↩