关于MapReduce
1 开发MapReduce应用¶
1 The Configuration API¶
Components in Hadoop are configured using Hadoop’s own configuration API. An instance of the org.apache.hadoop.conf.Configuration represents a collection of configuration properties and their values.
Configurations read their properties from XML files, which have a simple structure for defining name-value pairs.
Combining Resources¶
When more than one resource is used to define a Configuration, properties added later override the earlier definitions. However, properties that are marked as final cannot be overridden in later definitions.
Configuration conf = new Configuration();
conf.addResource("configuration-1.xml");
conf.addResource("configuration-2.xml");
assertThat(conf.getInt("size", 0), is(12));
assertThat(conf.get("weight"), is("heavy"));
<?xml version="1.0"?>
<configuration>
<property>
<name>color</name>
<value>yellow</value>
<description>Color</description>
</property>
<property>
<name>size</name>
<value>10</value>
<description>Size</description>
</property>
<property>
<name>weight</name>
<value>heavy</value>
<final>true</final>
<description>Weight</description>
</property>
<property>
<name>size-weight</name>
<value>${size},${weight}</value>
<description>Size and weight</description>
</property>
</configuration>
<?xml version="1.0"?>
<configuration>
<property>
<name>size</name>
<value>12</value>
</property>
<property>
<name>weight</name>
<value>light</value>
</property>
</configuration>
Variable Expansion¶
Configuration properties can be defined in terms of other properties, or system properties. For example, the property size-weight in configuration-1.xml file is defined as ${size}$, ${weight}$.
2 Setting Up the Development Environment¶
The first step is to create a project so you can build MapReduce programs and run them in local (standalone) mode from the command line or within your IDE.
Using the Maven POM to manage your project is an easy way to start. Specifically, for building MapReduce jobs, you only need to have the hadoop-client dependency, which contains all the Hadoop client-side classes needed to interact with HDFS and MapReduce. For running unit tests, use junit, and for writing MapReduce tests, use mrunit. The hadoop-minicluster library contains the “mini-” clusters that are useful for testing with Hadoop clusters running in a single JVM.
Managing Configuration¶
When developing Hadoop applications, it is common to switch between running the application locally and running it on a cluster.
One way to accommodate these variations is to have different versions of Hadoop configuration files and use them with the -conf command-line switch.
For example, the following command shows a directory listing on the HDFS server running in pseudodistributed mode on localhost:
$ hadoop fs -conf conf/hadoop-localhost.xml -ls
Another way of managing configuration settings is to copy the etc/hadoop directory from your Hadoop installation to another location, place the *-site.xml configuration files there (with appropriate settings), and set the HADOOP_CONF_DIRenvironment variable to the alternative location. The main advantage of this approach is that you don’t need to specify -conf for every command.
4 Running Locally on Test Data¶
Running a Job in a Local Job Runner¶
Using the Tool interface, it’s easy to write a driver to run our MapReduce job for finding the maximum temperature by year.
public class MaxTemperatureDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.err.printf("Usage: %s [generic options] <input> <output>\n",
getClass().getSimpleName());
ToolRunner.printGenericCommandUsage(System.err);
return -1;
}
Job job = new Job(getConf(), "Max temperature");
job.setJarByClass(getClass());
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxTemperatureMapper.class);
job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new MaxTemperatureDriver(), args);
System.exit(exitCode);
}
}
From the command line, we can run the driver by typing:
Testing the Driver¶
5 Running on a Cluster¶
packaging a job¶
In a distributed setting, a job's classes must be packaged into a job JAR file to send to the cluster. Creating a job JAR file is conveniently achieved using build tools, such as Maven.
<!-- Make this jar executable -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.0.2</version>
<configuration>
<outputDirectory>${basedir}</outputDirectory>
</configuration>
</plugin>
在Intellij IDEA中提交Job
在resource文件夹中放入Hadoop 配置文件/或者将,并且在用job.setJar()方法设置Jar即可。
Retrieving the Results¶
The hadoop fs -getmerge command gets all the files in the directory specified in the source pattern and merges them into a single file on the local filesystem:
hadoop fs -getmerge /flowsum/output localfile
Hadoop Logs¶
| Logs | Primary audience | Description |
|---|---|---|
| System daemon logs | Administrators | Each Hadoop daemon produces a logfile (using log4j) and another file that combines standard out and error. Written in the directory defined by the HADOOP_LOG_DIR environment variable. |
| HDFS audit logs | Administrators | A log of all HDFS requests, turned off by default. Written to the namenode’s log, although this is configurable. |
| MapReduce job history logs | Users | A log of the events (such as task completion) that occur in the course of running a job. Saved centrally in HDFS. |
| MapReduce task logs | Users | Each task child process produces a logfile using log4j (called syslog), a file for data sent to standard out (stdout), and a file for standard error (stderr). Written in the userlogs subdirectory of the directory defined by the YARN_LOG_DIR environment variable. |
Remote Debugging¶
6 Tuning a Job¶
2 MapReduce工作机制¶
1 Anatomy of a MapReduce Job Run¶
At the highest level, there are five independent entities:
- The client: submits the MapReduce job.
- The YARN resource manager: coordinates the allocation of compute resources on the cluster.
- The YARN node managers: launch and monitor the compute containers on machines in the cluster.
- The MapReduce application master: coordinates the tasks running the MapReduce job. The application master and the MapReduce tasks run in containers that are scheduled by the resource manager and managed by the node managers.
- HDFS: sharing job files between the other entities.
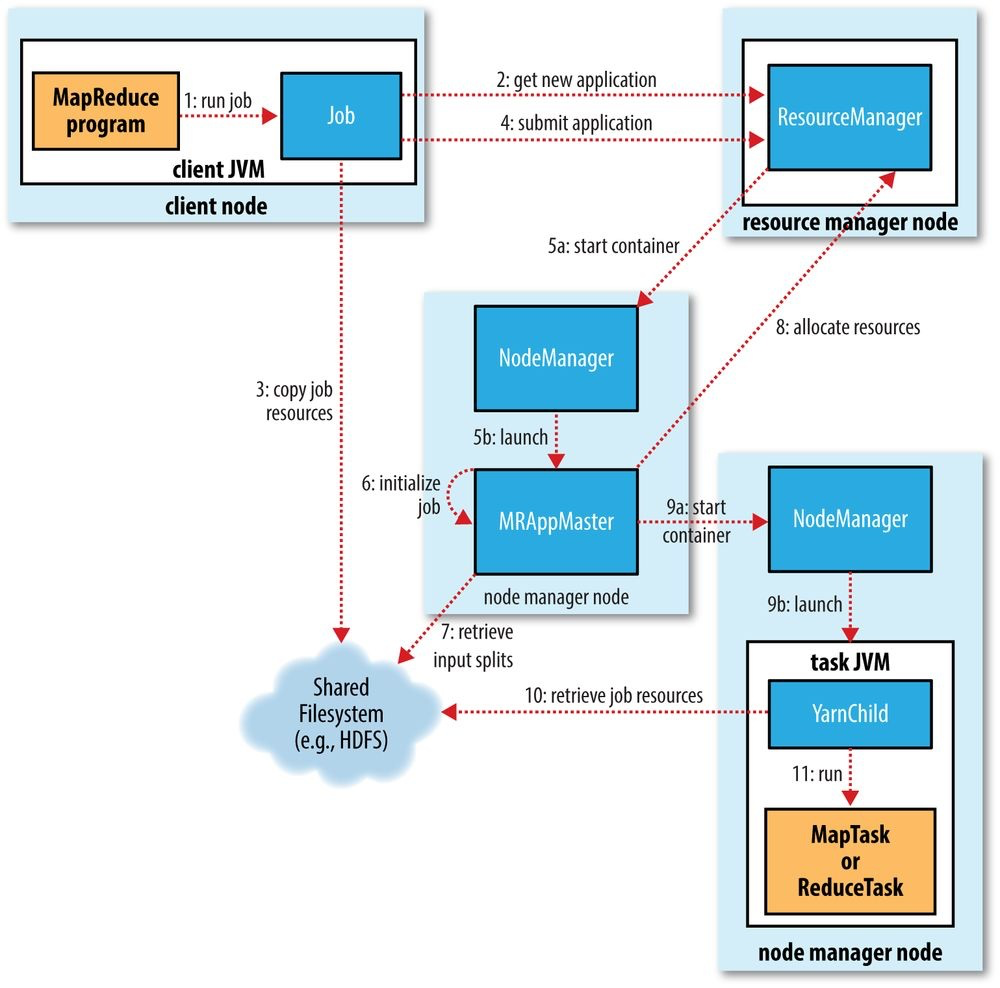
- Step 1: The
submit()method onJobcreates an internalJobSubmitterinstance and callssubmitJobInternal()on it. - Step 2: Ask the resource manager for a new application ID, used for MapReduce job ID.
- Step 3: Copies the resources needed to run the job, including the job JAR file, the configuration file, and the computed input splits, to the shared filesystem in a directory named after the job ID.
- Step 4: Submits the job by calling
submitApplication()on the resource manager. - Step 5: The YARN scheduler allocates a container, and the resource manager then launches the application master's process there, under the the node manager's management.
- Step 6: The application master (
MRAppMaster) initializes the job by creating a number of bookkeeping objects to keep track of the job's progress, as it will receive progress and completion reports from the tasks. - Step 7: The application master retrieves the input splits computed in the client from the shared filesystem, and then creates a map task object for each split, as well as a number of reduce task objects. Then it must decide how to run the tasks: run as an uber task(run the tasks in the same JVM)?
- Step 8: If the job does not qualify for running as uber task, then the application master requests container for all the map and reduce tasks in the job from the resource manager. Requests also specify memory requirements and CPUs for tasks.
- Step 9: The application master starts the container.
- Step 10: The task is executed by a Java application whose main class is
YarnChild. It localizes the resources that the task needs (job configuration and JAR file, etc). - Step 11: Finally,
YarnChildruns the map or reduce task.
2 Shuffle and Sort¶
MapReduce makes the guarantee that the input to every reducer is sorted by key. The process by which the system performs the sort and transfers the map outputs to the reducers as inputs, is known as the shuffle.
The Map Side¶
- Each map task has a circular memory buffer(环形缓冲区) that it writes the output to.
- When the contents of the buffer reach a certain threshold size, a background thread will start to spill the contents to disk.
- Before it writes to disk, the thread first divides the data into partitions(分区) corresponding to the reducers that they will ultimately be sent to.
- Within each partition, the background thread performs an in-memory sort by key, and if there is a combiner function, it is run on the output of the sort.
- Before the task is finished, the spill files are merged into a single partitioned and sorted output file.
- It is often a good idea to compress the map output as it is written to disk, because doing so makes it faster to write to disk, saves disk space, and reduces the amount of data to transfer to the reducer.
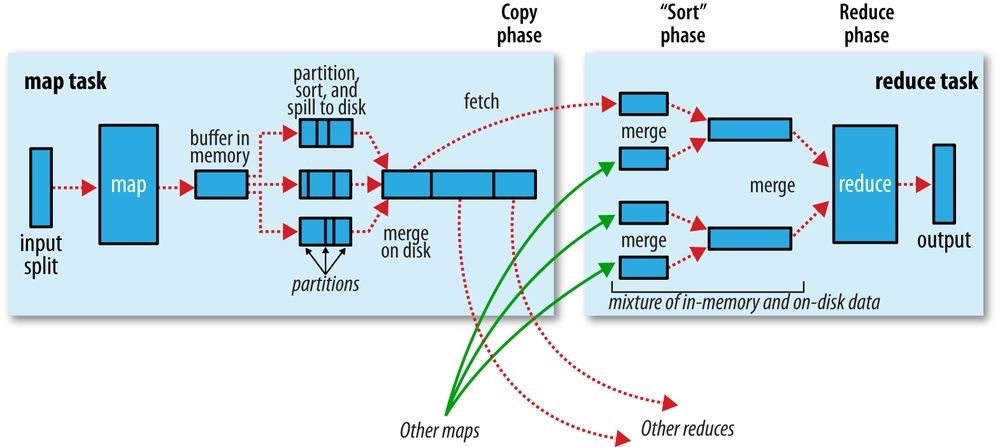
The Reduce Side¶
- copy phase: the reduce task starts copying outputs as soon as the tasks completes.
- Map outputs are copied to the reduce task JVM’s memory if they are small enough; otherwise, they are copied to disk.
- As the copies accumulate on disk, a background thread merges them into larger, sorted files. This saves some time merging later on.
- merge phase: merges the map outputs, maintaining their sort ordering, When all the map outputs have been copied. It is done in rounds.(Figure below) .
- reduce phase: directly feeding the reduce function.
- The output of the reduce phase is written directly to the output filesystem, typically HDFS.
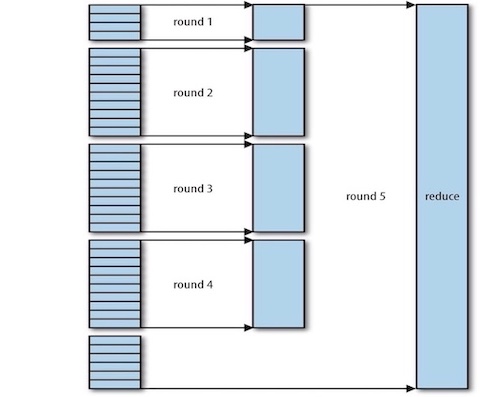
Efficiently Merging 40 File Segments With A Merge Factor Of 10
Configuration Tuning¶
4 Task Execution¶
3 MapReduce类型和格式¶
1 MapReduce Types¶
The map and reduce functions in Hadoop MapReduce have the following general form:
map: (K1, V1) → list(K2, V2)
reduce: (K2, list(V2)) → list(K3, V3)
why can’t the types be determined from a combination of the mapper and the reducer?
The answer has to do with a limitation in Java generics: type erasure means that the type information isn’t always present at runtime, so Hadoop has to be given it explicitly.
默认的MapReduce作业¶
默认的mapper是Mapper类,它将输入的键(文件中每行中开始的偏移量,LongWritable)和值(文本行, Text)原封不动地写入到输出中。
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
protected void map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
默认的partitioner是HashPartitioner,它对每条记录的键进行哈希操作以决定该记录属于哪个分区。每个分区由一个reduce任务处理,所以分区数等于作业的reduce任务个数。
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> {
public void configure(JobConf job) {}
public int getPartition(K2 key, V2 value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
由于默认情况下只有一个reducer,因此也就只有一个分区,在这种情况下,由于所有数据都放入同一个分区,partitioner操作将变得无关紧要了。但是,如果有多个reducer任务,则partitioner非常重要。
默认的reducer是Reducer类型,它把所有的输入写入到输出中。默认的输出格式为TextOutputFormat,它将键和值转换成字符串并用制表符分隔开,然后一条记录一行地进行输出。
public class Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {
protected void reduce(KEYIN key, Iterable<VALUEIN> values, Context context
) throws IOException, InterruptedException {
for(VALUEIN value: values) {
context.write((KEYOUT) key, (VALUEOUT) value);
}
}
2 输入格式¶
输入分片和格式¶
An input split(输入分片) is a chunk of the input that is processed by a single map. Each map processes a single split. Each split is divided into records(记录,a key-value pair). Splits and records are logical: input files are not physically split into chunks. In a database context, a split might correspond to a range of rows from a table and a record to a row in that range.
Input splits are represented by the Java class InputSplit:
public abstract class InputSplit {
public abstract long getLength()
throws IOException, InterruptedException;
public abstract String[] getLocations()
throws IOException, InterruptedException;
}
Note
A split doesn't contain the input data; it is just a reference to the data.
An InputFormat is responsible for creating the InputSplits and dividing them into records.
public abstract class InputFormat<K, V> {
// Logically split the set of input files for the job.
public abstract List<InputSplit> getSplits(JobContext context)
throws IOException, InterruptedException;
// Create a record reader for a given split. The framework will call
// RecordReader.initialize(InputSplit, TaskAttemptContext)} before
// the split is used.
public abstract RecordReader<K,V>
createRecordReader(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException;
}
The client running the job calculates the splits for the job by calling getSplits(), then sends them to the application master, which uses their storage locations to schedule map tasks that will process them on the cluster. The map task passes the split to the createRecordReader() method on InputFormat to obtain a RecordReader for that split.
A RecordReader is little more than an iterator over records, and the map task uses one to generate record key-value pairs, which it passes to the map function.
For the Mapper's run() method, after running setup(), the nextKeyValue() is called repeatedly on the Context to populate the key and value objects for the mapper. The key and value are retrieved from the RecordReader by way of the Context and are passed to the map() method for it to do its work.
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
cleanup(context);
}
}
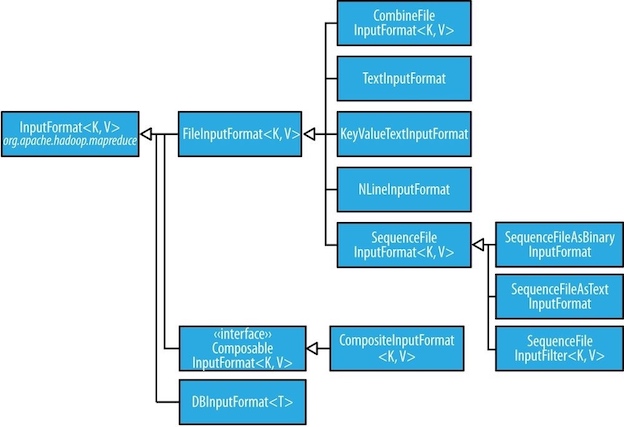
FileInputFormat¶
FileInputFormat is the base class for all implementations of InputFormat that use files as their data source. It provides two things:
- input paths: a collection of paths
- set by
addInputPath,addInputPaths,setInputPaths
- set by
- input splits: splits only large files (larger than split size, normally the size of an HDFS block).
- The split size is calculated by
max(minimumSize, min(maximumSize, blockSize), whereminimumSizeandmaximumSizeare minimum(usually 1 byte) and maximum (usually,Long.max.MAX_VALUE) size in bytes for a file split.
- The split size is calculated by
Hadoop works better with a small number of large files than a large number of small files. One reason for this is that FileInputFormat generates splits in such a way that each split is all or part of a single file.
CombineFileInputFormat¶
如果文件很小并且文件数量很多,由于FileInputFomart为每个文件产生一个分片,那么会有很多map任务,造成了额外开销。使用CombineFileInputFormat可以把多个文件打包到一个分片中以便每个mapper可以处理更多的数据。
如果可能的话,应该尽量避免许多小文件的情况。因为许多小文件会增加作业的寻址时间,也会浪费namenode的内存。一个可以减少大量小文件的方法是使用顺序文件(sequence file)将这些文件合并成一个或多个大文件:将文件名作为键,文件内容作为值。
将若干个小文件打包成顺序文件
public class SmallFilesToSequenceFileConverter {
static class SequenceFileMapper
extends Mapper<NullWritable, BytesWritable, Text, BytesWritable> {
private Text filenameKey;
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
InputSplit split = context.getInputSplit();
Path path = ((FileSplit) split).getPath();
filenameKey = new Text(path.toString());
}
@Override
protected void map(NullWritable key, BytesWritable value, Context context)
throws IOException, InterruptedException {
context.write(filenameKey, value);
}
}
@Override
public int run(String[] args) throws Exception {
Job job = JobBuilder.parseInputAndOutput(this, getConf(), args);
if (job == null) {
return -1;
}
job.setInputFormatClass(WholeFileInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(BytesWritable.class);
job.setMapperClass(SequenceFileMapper.class);
return job.waitForCompletion(true) ? 0 : 1;
}
}
Text Input¶
TextInputFormat¶
TextInputFormat is the default InputFormat.
- Each record is a line of input.
- The key is the byte offset (字节偏移量) within the file.
- The value is the contents of the line, excluding any line terminators (e.g., newline or carriage return), and is packaged as a
Textobject.
THE RELATIONSHIP BETWEEN INPUT SPLITS AND HDFS BLOCKS
The logical records that FileInputFormats define usually do not fit neatly into HDFS blocks. This has no bearing on the functioning of programs. Data-local maps will perform some remote reads.

KeyValueTextInputFormat¶
Using KeyValueTextInputFormat, each line in a file is a key-value pair, separated by a delimiter such as a tab character. The separator can be specified by the mapreduce.input.keyvaluelinerecordreader.key.value.separator property.
NLineInputFormat¶
Using NLineInputFormat, mappers receive a fixed number of lines of input. Like with TextInputFormat, the keys are the byte offsets within the file and the values are the lines themselves.
Multiple Inputs¶
MultipleInputs allows to specify which InputFormat and Mapper to use on a per-path basis. For example, if you had weather data from the UK Met Office that you wanted to combine with the NCDC data for your maximum temperature analysis, you might set up the input as follows:
MultipleInputs.addInputPath(job, ncdcInputPath,
TextInputFormat.class, MaxTemperatureMapper.class);
MultipleInputs.addInputPath(job, metofficeInputPath,
TextInputFormat.class, MetOfficeTemperatureMapper.class);
Binary Input¶
SequenceFileInputFormat¶
Using SequenceFileInputFormat, the keys and values are determined by the sequence file.
3 Output Formats¶
TextOuput¶
TextOutputFormat is the default output format, which writes records as lines of text. Its keys and values may be of any type, since TextOutputFormat turns them into strings by calling toString() on them. Each key-value pair is separated by a tab character by default.
Multiple Outputs¶
FileOuputFormat及其子类产生的文件放在输出目录下。每个reducer一个文件并且文件由分区号命名:part-r-00000, part-r-00001, 等等。MultipleOuput累可以让每个reducer输出多个文件,采用name-m-nnnnn形式的文件名用于map输出,name-r-nnnnn形式的文件名用户reduce输出,其中name是由程序设定的任务名字,nnnnn是一个指明块号的整数(从00000开始)。
4 MapReduce特性¶
1 Counters¶
Counters are a useful channel for gathering statistics about the job: for quality control or for application-level statistics.
2 Sorting¶
Partial Sort¶
In the Default MapReduce Job, MapReduce will sort input records by their keys by default.
控制排列顺序
键的排列顺序是由RawComparator控制的,规则如下:
- 若属性
mapreduce.job.output.key.comparator.class已经显式设置,或者通过Job类的setSortComparatorClass()方法进行设置,则使用该类的实例; - 否则,键必须是
WritableComparable的子类,并使用针对该键类的已登记的comparator; - 如果还没有已登记的comparator,则使用
RawComparator: 它将字节流反序列化为一个对象,再由WritableComparable的CompareTo()方法进行操作(参见Hadoop IO)。
Total Sort¶
The naive answer to produce a globally sorted file using hadoop is to use a single partition. However, it is incredibly inefficient for large files, since one machine needs to process all of the output. The best way is to use a partitioner and keep partition sizes fairly even. A possible way to get a fairly even set of partitions is to sample the key space.
Secondary Sort¶
How to get the effect of sorting by value:
- Make the key a composite of the natural key and the natural value.
- The sort comparator should order by the composite key
- The partitioner and grouping comparator for the composite key should consider only the natural key for partitioning and grouping
计算每年的最高气温
public class MaxTemperatureUsingSecondarySort {
static class MaxTemperatureMapper extends Mapper<LongWritable, Text, IntPair, NullWritable> {
private NcdcRecordParser parser = new NcdcRecordParser();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
parser.parse(value);
if (parser.isValidTemperature())
context.write(new IntPair(parser.getYearInt(),
parser.getAirTemperature()), NullWritable.get());
}
}
static class MaxTemperatureReducer extends Reducer<IntPair, NullWritable, IntPair, NullWritable> {
@Override
protected void reduce(IntPair key, Iterable<NullWritable> values, Context context)
throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
public static class FirstPartitioner extends Partitioner<IntPair, NullWritable> {
@Override
public int getPartition(IntPair intPair, NullWritable nullWritable, int numPartitions) {
return Math.abs(intPair.getYear()*127) % numPartitions;
}
}
public static class KeyComparator extends WritableComparator {
protected KeyComparator() {
super(IntPair.class, true);
}
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
IntPair ip1 = (IntPair) w1;
IntPair ip2 = (IntPair) w2;
if (ip1.getYear() != ip2.getYear())
return ip1.getYear() - ip2.getYear();
return ip2.getTemperature() - ip1.getTemperature();
}
}
public static class GroupComparator extends WritableComparator {
protected GroupComparator() {
super(IntPair.class, true);
}
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
IntPair ip1 = (IntPair) w1;
IntPair ip2 = (IntPair) w2;
return ip1.getYear() - ip2.getYear();
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(MaxTemperatureUsingSecondarySort.class);
job.setJar("/Users/larry/Documents/codes/bigdata/bigdata-1.0-SNAPSHOT.jar");
job.setMapperClass(MaxTemperatureMapper.class);
job.setPartitionerClass(FirstPartitioner.class);
job.setSortComparatorClass(KeyComparator.class);
job.setGroupingComparatorClass(GroupComparator.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(IntPair.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://centos1:9000/ncdc/input/ncdc"));
Path outputPath = new Path("hdfs://centos1:9000/ncdc/output/");
FileOutputFormat.setOutputPath(job, outputPath);
FileSystem fs = FileSystem.get(new URI("hdfs://centos1:9000"), conf, "root");
if (fs.exists(outputPath)) fs.delete(outputPath, true);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
3 Joins¶
Tip
Writing MapReduce program from scratch to perform joins between large datasets is fairly involved. Using a higher-level framework such as Pig, Hive or Spark is a better choice.
连接操作如果由mapper执行,则称为map端连接(map-side join); 如果由reducer执行,则称为reduce端连接(reduce-side join)。至于到底采用哪种连接,取决于数据的组织方式。
map端连接¶
reduce端连接¶
4 Side Data Distribution¶
Side data can be defined as extra read-only data needed by a job to process the main dataset. The challenge is to make side data available to all the map or reduce tasks (which are spread across the cluster) in a convenient and efficient fashion.
Distributed Cache¶
Distribute cache mechanism provides a service for copying files and archives to the task nodes in time for the tasks to use them when they run.
When you launch a job, Hadoop copies the files to the HDFS. Then, before a task is run, the node manager copies the files from the HDFS to a local disk -- the cache -- so the task can access the files. MapReduce always create a symbolic link from the task's working directory to every file or archive added to the distributed cache, so you can directly access the localized file by name.